Introduction
Databricks has become the top unified analytics platform, changing the way data engineers and analysts manage complex data workflows with its advanced distributed computing setup. It integrates smoothly with major cloud services like Azure and AWS, using Apache Spark's power to handle large data processes efficiently. One of its standout features is the ability to perform multiple tables write operations at once, supported by Delta Lake's data consistency features.
Key Advantages:
- Distributed Processing Power: Uses Apache Spark’s cluster setup to perform multiple tables writes at the same time, greatly speeding up large-scale data tasks.
- Enterprise-Grade Reliability: Delta Lake’s transaction log ensures data consistency and safety by supporting rollback and maintaining data integrity, even in complex multi-table operations.
How Can We Utilize Databricks to Write in Multiple Tables?
Writing data into multiple tables using Databricks includes many key steps. Below is a detailed guide on how to achieve this, with easy examples to help you understand the process.
1. Set Up Your Databricks Environment
Before you start writing data to multiple tables, make sure you have your Databricks environment set up. Depending on your cloud provider, you can use Azure Databricks or AWS Databricks.
2. Load Your Data

The first step in writing to multiple tables is to load your data into Databricks. This can be done by using different data sources, for example CSV, JSON, Parquet files or databases.
from pyspark.sql import SparkSession
# Initialize Spark session spark =
SparkSession.builder.appName(“MultipleTables”).getOrCreate()
# Load data from a CSV file
data = spark.read.csv(“/path/to/your/data.csv”, header=True, inferSchema=True)
3. Data Transformation
Once your data is loaded, you require to innovate it so that it can fit the schema of your target tables. Databricks, powered by Apache Spark, provides efficient transitioning capabilities.
# Transform data
transformed_data = data.withColumnRenamed(“old_column_name”, “new_column_name”)
4. Writing Data to Multiple Tables
To write data into multiple tables, you can use the write method provided by Spark DataFrame. You can specify different tables as targets and write the data accordingly.
# Writing to the first table
transformed_data.filter(transformed_data[“category”] ==
“A”).write.format(“delta”).mode(“overwrite”).save(“/path/to/tableA”)
# Writing to the second table transformed_data.filter(transformed_data[“category”] == “B”).write.format(“delta”).mode(“overwrite”).save(“/path/to/tableB”)
n this example, data is filtered based on the category and then written to two different tables, tableA and tableB.
5. Using Delta Lake for Reliability
Delta Lake is an open-source storage layer that brings reliability to data lakes, integrates flawlessly with Databricks. It provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing.
# Create Delta tables
delta_path_A = “/path/to/delta_tableA”
delta_path_B = “/path/to/delta_tableB”
transformed_data.filter(transformed_data[“category”] == “A”).write.format(“delta”).mode(“overwrite”).save(delta_path_A) transformed_data.filter(transformed_data[“category”] == “B”).write.format(“delta”).mode(“overwrite”).save(delta_path_B)
Delta Lake ensures that your data is reliable and consistent. This reliability and consistency make it easier to manage multiple tables.
6. Automation with Databricks Jobs
Databricks Jobs allow you to automate your ETL processes, including writing to multiple tables. You can schedule jobs to run at specific intervals. You can do all that along with ensuring that your data is always up to date.
# Example of creating a Databricks job using the REST API
import requests
import json
url = “https://<databricks-instance>/api/2.0/jobs/create”
headers = {
“Authorization”: “Bearer <your-access-token>”,
“Content-Type”: “application/json” }
job_config = {
“name”: “WriteToMultipleTablesJob”,
“new_cluster”: {
“spark_version”: “7.3.x-scala2.12”,
“num_workers”: 2,
“node_type_id”: “i3.xlarge”, },
“notebook_task”: {
“notebook_path”: “/Users/your_username/WriteToMultipleTables” } }
response = requests.post(url, headers=headers,
data=json.dumps(job_config)) print(response.json())
Performance Optimization Strategies for Multiple Table Operations
When writing to multiple tables in Databricks, speed matters a lot. The key is to use parallel processing to write to different tables at the same time instead of one by one. You can also partition your data smartly so that each table gets exactly what it needs without extra processing. Caching frequently used data in memory helps avoid repeated calculations. Don't forget to use Delta Lake's optimized features to keep your tables running fast even after many write operations.
Error Handling and Rollback Mechanisms in Multi-Table Scenarios
Things can go wrong when writing to multiple tables, so you need a safety net. Databricks lets you wrap all your table writes in transactions, which means if one fails, everything gets rolled back automatically. Always check each write operation for errors before moving to the next table. Set up proper logging so you can see exactly where things went wrong. This way, your data stays consistent, and you don't end up with half-completed operations messing up your database.
Setting Up Multi-Table Write Operations in Databricks
Getting started with multi-table writes in Databricks is easier than you think. First, create your Spark session and connect to your target databases or storage locations. Define your Data frames for each table you want to write to, making sure the schemas match your destination tables. Use Databricks' built-in connectors to establish connections to different data sources. Plan your write sequence carefully - some tables might depend on others, so order matters for maintaining data integrity.
Benefits of Using Databricks for Writing to Multiple Tables
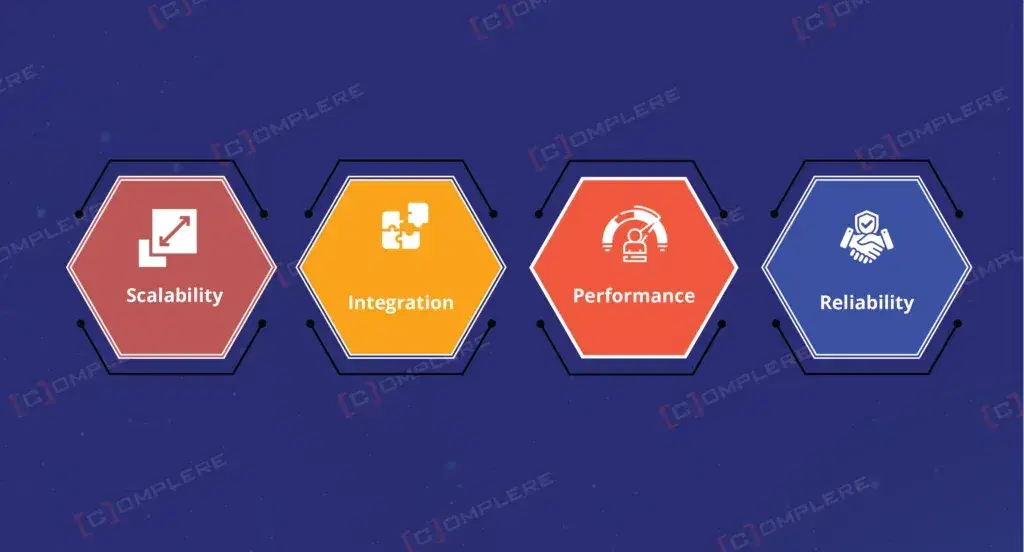
After understanding how to use Databricks to write multiple tables, let us understand the benefits of using Databricks for writing multiple tables.
- Scalability: Databricks can manage big volumes of data efficiently. This management capability makes it an ideal resource for writing to multiple tables. Whether you're handling millions of records or terabytes of data, the platform automatically scales resources up or down based on your workload needs.
- Integration: Whether you are using Azure Databricks or AWS Databricks, the platform integrates flawlessly with other data sources and tools. You can easily connect to databases, data lakes, APIs, and business applications without complex setup processes. This seamless connectivity means your multi-table operations work smoothly across your entire data ecosystem.
- Performance: Powered by Apache Spark, Databricks provides high-performance data processing capabilities. The distributed computing engine processes multiple table writes simultaneously, dramatically reducing the time needed for complex operations. Auto-scaling clusters ensure optimal performance even during peak data processing times.
- Reliability: Delta Lake guarantees data reliability and consistency. These two elements are important for managing multiple tables. Built-in transaction support means your writes either complete successfully across all tables or fail safely without corrupting any data.
Using Databricks properly for writing data into multiple tables is a must have solution for data engineers and analysts. The platform’s scalability and performance, combined with the reliability of Delta Lake, make it a technologically advanced solution for complicated data management tasks. Whether you are working on Azure Databricks or AWS Databricks, the ease of integration and automation capabilities further improve productivity and efficiency.
Conclusion
Databricks provides a capable and efficient way to write data into multiple tables. By using its capabilities, businesses can manage big datasets with ease, by making sure that their data is consistent and reliable. With the integration of Delta Lake and the automation features of Databricks Jobs, the platform is a top choice for modern data engineering tasks.
Click here to transform your business with expert data solutions with 9+ years of industry expertise.