Introduction:
Struggling with data performance? The reason can be your data pipelines’s slow proessing or producing inconsistent results. Databricks is one of the most useful platforms for data engineering and analytics. It can be perfect solution for you to recover and optimize data performance. Known for its flawless integration with different cloud platforms including Azure Databricks and AWS Databricks. Databricks provides amazing features for improving the efficiency of data workflows, reducing costs, and scalability.
Databricks experts know help you transform your data operations and achieve optimal performance. Whether you’re comparing Databricks vs Snowflake or interested in its AI capabilities, these insights will help you maximize the platform’s efficiency and unlock new opportunities for success.
Why Databricks Performance Matters
Effective data performance is the backbone of successful decision-making. Poor data performance can delay reports, obscure insights, and lead to suboptimal business outcomes. That’s why Databricks has become a top choice for organizations looking to recover and boost their data operations.
Databricks is not just another cloud platform. It’s a unified analytics environment that helps data engineers, analysts, and scientists collaborate efficiently.
By running on top of Azure Databricks or AWS Databricks, companies can scale operations without worrying about underlying infrastructure. This makes it a top competitor in the data platform arena. But what are the hidden tricks to get the most out of Databricks? Let’s explore!
1. Leverage Delta Lake for Reliable and Faster Data Processing
One of the best-kept secrets of Databricks is its Delta Lake functionality, which optimizes data lake performance. Delta Lake adds a robust layer of data reliability, ensuring that your data is always accurate and processed faster. Whether you are dealing with streaming or batch data, Delta Lake makes sure that you get consistent data without any loss.
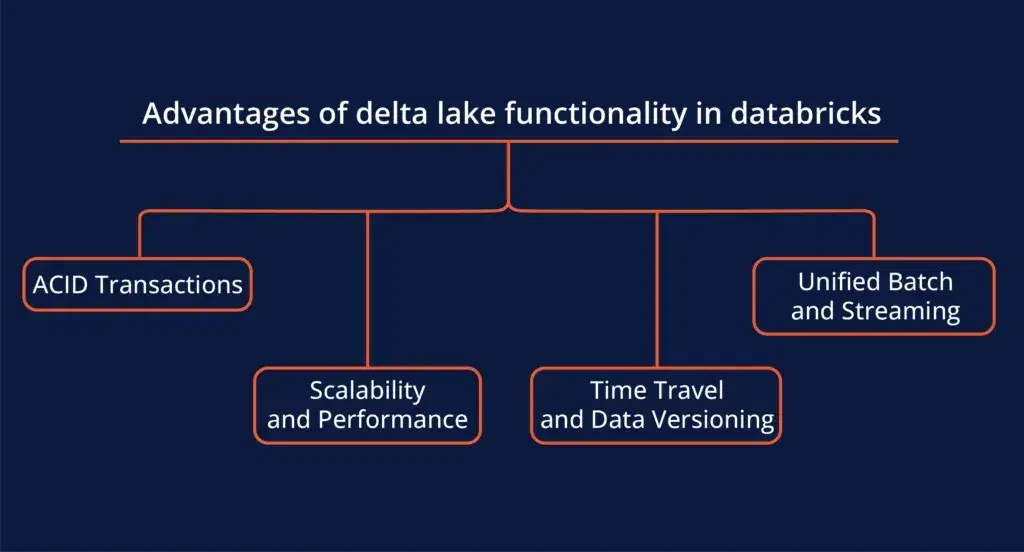
Secret Advantage:
- ACID Transactions: Delta Lake offers ACID (Atomicity, Consistency, Isolation, Durability) transactions, meaning your data stays reliable even during simultaneous reads and writes.
- Version Control: Delta Lake’s versioning capabilities allow you to track changes, roll back to previous versions, and recover corrupted data instantly.
This functionality is especially useful when compared to Databricks competitors, as it provides real-time analytics and fault-tolerant data pipelines.
2. Maximize Resource Utilization with Auto-Scaling Clusters
Managing clusters in Databricks is critical for ensuring maximum efficiency in data processing. Auto-scaling clusters are one of Databricks’ hidden gems, allowing you to adjust your cluster size dynamically based on the workload. This reduces unnecessary costs and optimizes resources.
Secret Advantage:
- Automated Scaling: Whether you’re running an intense machine learning model or processing large datasets, auto-scaling adjusts the cluster size to meet real-time needs without manual intervention.
- Reduce Idle Time: By automatically terminating idle clusters, you can avoid paying for unused resources, which is particularly useful if you’re running AWS Databricks or Azure Databricks in a cost-conscious environment.
This feature also sets Databricks apart in the ongoing Databricks vs Snowflake debate. Snowflake focuses more on warehousing, while Databricks provides flexibility for big data processing and machine learning tasks
3. Efficient Machine Learning with Databricks AI
For companies looking to dive into machine learning, Databricks AI offers cutting-edge tools that accelerate AI model development and deployment. One of the secrets to maximizing Databricks AI is its integration with existing data pipelines, allowing you to train models on live data rather than stale historical data.
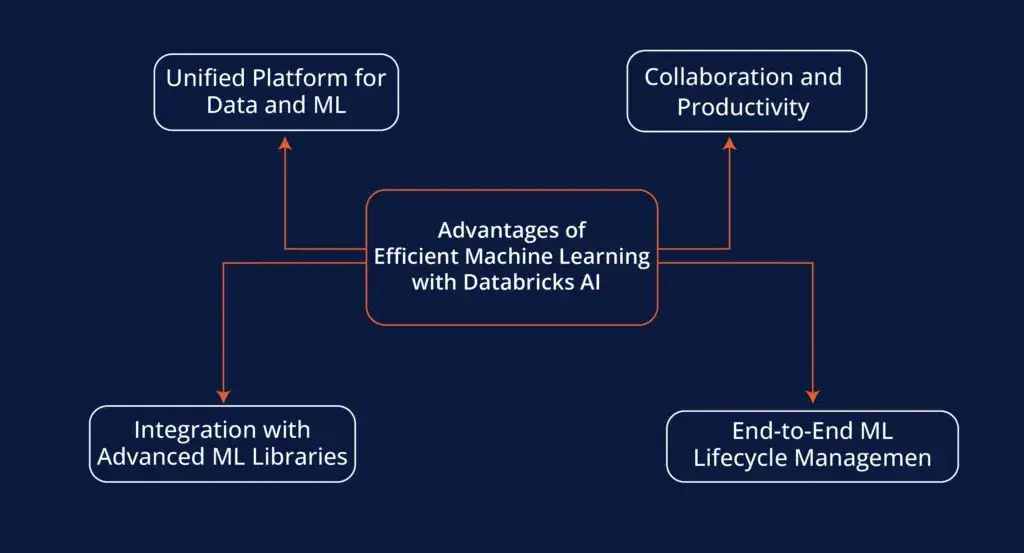
Secret Advantage:
- Seamless Model Training: Databricks AI allows you to train machine learning models directly on your live data, giving you real-time predictions and insights.
- Integration with AutoML: If you’re new to machine learning, Databricks AI also supports AutoML (Automated Machine Learning), helping you build robust models without deep AI expertise.
For companies comparing Databricks vs Snowflake, the AI capabilities are a clear differentiator. Snowflake is primarily a data warehousing solution, whereas Databricks excels in advanced analytics and machine learning.
4. Improve Query Speed with Caching
One of the easiest ways to optimize data performance in Databricks is by using caching effectively. Caching stores frequently accessed data in memory, so you don’t have to run the same query multiple times, drastically improving the speed of repetitive tasks.
Secret Advantage:
- DataFrame Caching: By caching DataFrames, you eliminate the need to recompute results, making your pipeline significantly faster.
- Selective Caching: Not all data should be cached. Focus on frequently used data to avoid wasting memory on rarely accessed information.
This feature is especially beneficial in cloud environments like AWS Databricks and Azure Databricks, where reducing computation time directly impacts cost savings.
5. Automate Workflows with the Databricks API
The Databricks API is an underutilized feature that can greatly enhance productivity through automation. With the Databricks API, you can automate repetitive tasks, such as starting or stopping clusters, executing notebooks, and scheduling jobs.
Secret Advantage:
- Custom Automation: Use the API to create custom workflows that automatically execute at certain intervals, freeing up time for more important tasks.
- Integration with Other Tools: The Databricks API can easily be integrated into your existing tools or CI/CD pipelines, allowing you to automate data engineering tasks end-to-end.
Compared to Databricks competitors, this level of automation puts Databricks ahead, especially when working with complex, multi-step data pipelines that need constant monitoring and adjustments.
6. Collaborate Across Teams Seamlessly
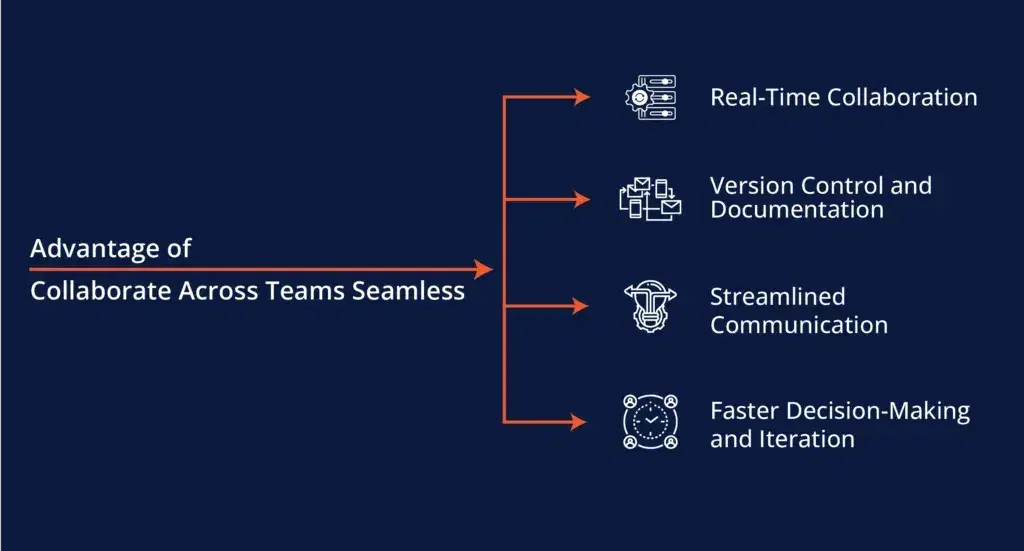
One of the best features of Databricks is its collaborative environment, which is often overlooked by new users. Databricks allows data engineers, analysts, and data scientists to work together in a shared workspace, improving communication and reducing delays in the data processing lifecycle.
Secret Advantage:
- Real-Time Collaboration: Multiple team members can work on the same notebooks and pipelines simultaneously, making collaboration smooth and error-free.
- Version Control: Keep track of all changes and easily roll back to previous versions if needed. This is a big deal for teams working on complex data models and transformations.
By improving collaboration, Databricks reduces bottlenecks that commonly occur in data workflows, allowing teams to deliver insights faster.
7. Databricks vs Snowflake: Performance and Efficiency
A common question is whether to use Databricks or Snowflake. The answer lies in your organization’s needs. Snowflake is an excellent data warehouse solution with its focus on structured data and SQL-based queries, but Databricks offers more flexibility and performance for big data processing and machine learning.
Secret Advantage:
- For Advanced Analytics: If your focus is on data engineering, machine learning, or real-time data analytics, Databricks is the superior choice.
- For Data Warehousing: If you need a straightforward data warehousing solution without AI capabilities, Snowflake may be more cost-effective.
For companies needing advanced AI or machine learning, Databricks AI clearly outperforms Snowflake, making it the better choice for future-proof data solutions.
8. Monitor Performance with Built-In Tools
Databricks provides various monitoring tools to help you keep an eye on your cluster and pipeline performance. These tools are invaluable for diagnosing issues and optimizing workflows before they affect your data results.
Secret Advantage:
- Cluster Monitoring: Track CPU and memory usage in real-time to ensure that your clusters are running efficiently.
- Job Monitoring: Keep tabs on job execution and set up automated alerts to notify you of any failures or performance drops.
Conclusion
Databricks is a powerhouse for improving data performance, offering flexibility, scalability, and real-time analytics capabilities. Whether you’re running Azure Databricks, AWS Databricks, or considering a comparison between Databricks vs Snowflake, these best-kept secrets will help you recover and boost your data performance.
From leveraging Delta Lake and using the Databricks API to maximizing the power of Databricks AI, these strategies can transform your data operations. The more efficiently you manage your clusters, automate workflows, and utilize built-in tools, the better your data outcomes will be.
Ready to unlock the full potential of Databricks? Connect with our data experts today and discover how you can optimize your data workflows for maximum efficiency! Schedule a consultation now.